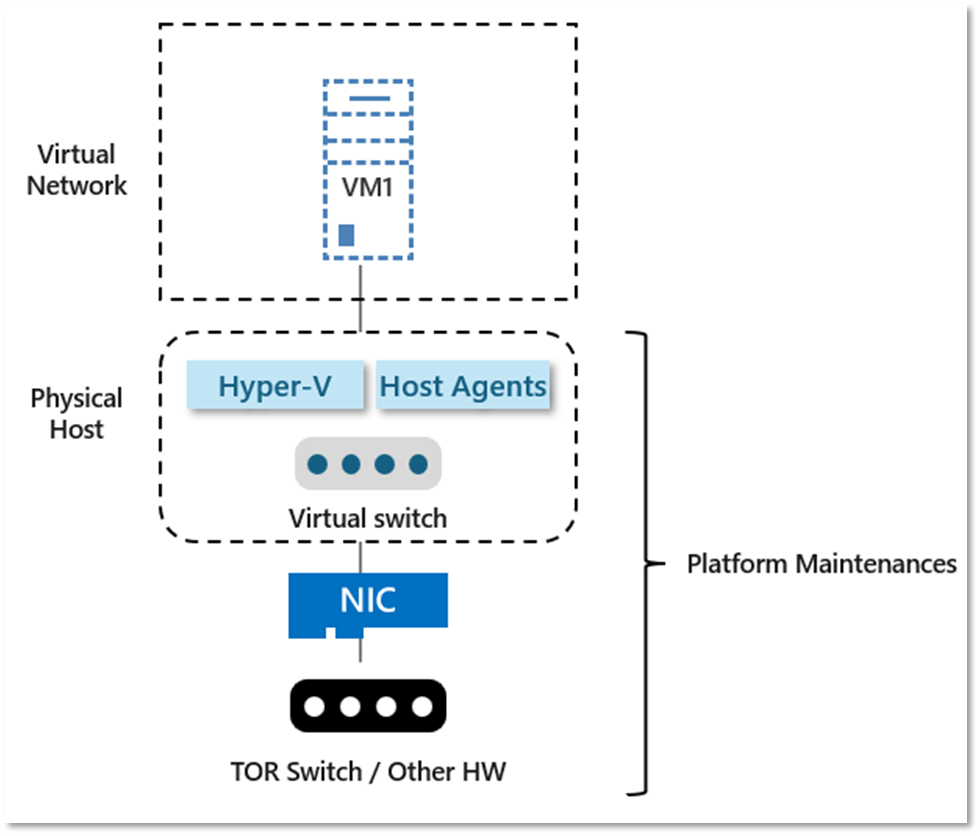
Azure регулярно обновляет свою платформу, чтобы улучшить инфраструктуру хоста для виртуальных машин, уделяя особое внимание надежности, производительности и безопасности. Обновления могут варьироваться от операционной системы, гипервизора, различных сетевых компонентов/агентов, развернутых на хосте, до вывода оборудования из эксплуатации:
Существует два типа обслуживания ВМ:
- Плановое обслуживание События — это периодические обновления, вносимые Microsoft в базовую платформу Azure. Большинство этих обновлений полностью прозрачны для клиентов. Однако некоторое обслуживание может привести к кратковременным зависаниям или снижению производительности, а в очень редких случаях может потребоваться перезагрузка.
- Внеплановое обслуживание События происходят, когда аппаратное обеспечение или физическая инфраструктура, лежащая в основе вашей виртуальной машины, каким-либо образом неисправна. Когда такая неудача произойдет благодаря прогнозному машинному обучениюплатформа Azure автоматически переносит (живую миграцию) вашу виртуальную машину с неработоспособного физического узла на новый исправный физический узел.
В случаях, когда динамическую миграцию использовать невозможно, виртуальная машина неожиданно простаивает (перезагружается).
В этой статье мы подробно рассмотрим методы, используемые для проведения планового технического обслуживания, а также то, что клиент может и не может контролировать.
Azure — палитра вариантов применения обновлений в зависимости от обновления и ограничений.
Чтобы углубиться в детали, Azure использует разные техники для обновлений в зависимости от типа обновления и ограничений, чтобы гарантировать минимальное влияние обновлений:

Источник: Inside Azure Innovations с Марком Руссиновичем | БКР214Х
- Горячее исправление – Это дает возможность вносить целевые изменения в работающий код без простоев. Все новые вызовы функции на хосте перенаправляются на обновленную версию этой функции.
- Живая миграция – Это предполагает перемещение работающей клиентской виртуальной машины с одного хоста на другой.
- ВМ-ПХУ – Обновление хоста с сохранением виртуальной машины
- Это приостанавливает работу виртуальных машин в памяти, программно перезагружает ОС и возобновляет работу виртуальных машин.
- Это наиболее эффективное обновление без перезагрузки, но, к счастью, оно встречается реже всего.
Azure может использовать один из вышеперечисленных методов, чтобы минимизировать влияние во время незапланированное обслуживание оборудования, неожиданные простои и плановое обслуживание.
Примечание. Выше не упоминается перезагрузка. Гостевые виртуальные машины перезагружаются только в том случае, если предыдущие методы использовать невозможно.
Вот краткое описание процедуры, используемой для управления обновлениями и обслуживанием хоста:

Здесь важно упомянуть, что все операции по обслуживанию, о которых мы только что говорили, могут выполняться в Azure в любое время, и клиенты не имеют контроля над тем, когда могут происходить такие обновления (которые вызывают зависания).
Контроль технического обслуживания – общий хост против выделенного хоста
По умолчанию, когда вы подготавливаете виртуальную машину в Azure, она размещается на случайном хосте в целевом регионе и зоне доступности, и этот хост используется несколькими виртуальными машинами от нескольких клиентов. Это то, что мы называем Общие хосты.
В дополнение к нашей модели хостинга по умолчанию с использованием общих хостов Microsoft также предоставляет вам возможность иметь выделенный хост, на котором могут размещаться только ваши виртуальные машины. Это предложение носит название Выделенный хост Azure и предлагает различные преимущества, среди которых:
- Изоляция рабочей нагрузки на выделенных физических серверах
- Контроль и видимость размещения рабочей нагрузки
- Больше контроля над обслуживанием, чем на общих хостах.
Хотя оба решения имеют свои плюсы и минусы, давайте сосредоточимся на последнем пункте: средствах управления обслуживанием.
Как объяснялось выше, для обновления различных компонентов инфраструктуры можно использовать несколько методов, и мы можем выделить две основные категории последствий:
- Обновления без перезагрузки (также известные как заморозки)
- Перезагрузка обновлений
При размещении на общем хосте клиентам предоставляется 35-дневное окно, в течение которого они могут планировать, когда должна произойти перезагрузка их виртуальной машины: в течение этого периода у них есть контроль над обновлениями Rebootful. По истечении срока действия Microsoft самостоятельно запланирует перезагрузку, и клиент будет уведомлен за несколько минут до того, как перезагрузка произойдет через Запланированные мероприятия (мы опишем этот механизм в следующем разделе).
Как упоминалось ранее, обновления без перезагрузки на общих хостах клиент не имеет над ними контроля и не может ничего планировать. Это означает, что на виртуальных машинах, работающих на общих хостах, зависания (обычно на пару секунд) могут произойти в любой момент.
Если недопустимо, чтобы рабочие нагрузки клиентов подвергались такого рода неконтролируемым зависаниям, то выделенный хостинг Azure может оказать большую помощь. На этих хостах функция Maintenance Control позволяет клиентам планировать все виды обновлений (без перезагрузки и с перезагрузкой) и применять их в предпочтительное время в течение 35-дневного периода.
Теперь, когда у вас есть лучшее представление о различных вариантах контроля обслуживания, давайте посмотрим, как управлять обновлениями на общих хостах.
Общий хост – как минимизировать влияние виртуальной машины на обслуживание?
Если необходима перезагрузка, клиенты уведомляются и даются сроки для самостоятельного начала обслуживания, обычно в течение 35 дней, если только это не является срочным. Видеть Обработка уведомлений о плановом техническом обслуживании.
Если перезагрузка не требуется, виртуальная машина либо приостанавливается, либо переносится в реальном времени на уже обновленный хост.
Некоторые приложения могут не переносить паузу даже на несколько секунд. Для этих приложений возможна альтернатива:
1) Ловите запланированные события за 15 минут до паузы.
РасписаниеСобытия является Служба метаданных экземпляра Azure (IMDS) API, который дает вашему приложению время подготовиться к обслуживанию виртуальной машины. Он обеспечивает предварительное уведомление за 15 минут до событий обслуживания (перезагрузка, повторное развертывание, замораживание, вытеснение, завершение), чтобы ваше приложение могло подготовиться к ним и ограничить сбои:

Службы на виртуальной машине могут отслеживать этот API для корректного завершения работы (и очистки соединения) до того, как событие будет выполнено.
Примечание. События расписания включаются, когда служба делает первые запросы на запрос событий. Первый ответ происходит с некоторой задержкой (~ 1 минута). Он отключается, если в течение 24 часов нет запроса к конечной точке.
2) Отказ от использования выделенного хоста Azure.
Как объяснялось ранее, выделенный хост Azure может быть решением для контроля над проведением технического обслуживания.
Как диагностировать сбои в доступности виртуальной машины?
Проект Флэш позволяет клиентам Azure обнаруживать и диагностировать текущие и завершенные нарушения доступности, включая деградацию виртуальных машин.
Доступность виртуальной машины Azure можно отслеживать с помощью:
- Граф ресурсов Azure – Для масштабного расследования: централизованное хранилище ресурсов и поиск по истории.
- Темы системы сетки событий – Для запуска срочных и критических мер по устранению последствий (повторное развертывание действий по перезапуску виртуальной машины).
- Azure Монитор – Чтобы отслеживать тенденции, агрегировать показатели платформы (ЦП, диск и т. д.) и настраивать точные оповещения на основе пороговых значений.
- Работоспособность ресурсов Azure – Для выполнения мгновенных и удобных проверок работоспособности пользовательского интерфейса портала для каждого ресурса.
При использовании Azure Resource Graph в таблице HealthResource заполняются два типа событий:
- Статусы работоспособности/доступности ресурсов
Обозначает состояние доступности виртуальной машины.
Могут принимать значения между Доступно | Недоступно | Неизвестный | Деградация:
{
"targetResourceType": "Microsoft.Compute/virtualMachines",
"previousAvailabilityState": “Unavailable",
"targetResourceId": ,
"occurredTime": ,
"availabilityState": "Available"
} - здоровье ресурсов/аннотации ресурсов
Предоставляет контекст для интерпретации причин изменения доступности виртуальной машины и принятия решительных мер в случае необходимости.
- Причина: Краткая информация о том, почему изменилась доступность виртуальной машины.
- Контекст: Платформа запущена | Клиент инициировал | ВМ инициирована | Неизвестно | Непригодный
- Категория: Планируется | Незапланированный | Неизвестный | Непригодный
- Сводка: Подробное описание действий и причины изменения доступности виртуальной машины.
- Тип воздействия: Перезагрузка во время простоя | Заморозка времени простоя | Деградировал | Информационный
{
"targetResourceType": "Microsoft.Compute/virtualMachines",
"targetResourceId": ,
"annotationName": "VirtualMachineHostRebootedForRepair",
"occurredTime": "2022-09-25T20:21:37.5280000Z",
"category": “Unplanned",
"summary": "We're sorry, your virtual machine isn't available because an unexpected failure on the host server. Azure has begun the auto-recovery process and is currently rebooting the host server. No additional action is required from you at this time. The virtual machine will be back online after the reboot completes.",
"context": “Platform Initiated",
"reason": "Unexpected host failure",
"impactType”: “Downtime Reboot"
} Примеры полезных запросов KQL к таблице HealthResources: доступный.
Заключение
В этой статье мы подробно описали две модели хостинга (общие хосты и выделенные хосты) и соответствующие им варианты планового и внепланового обслуживания, а также средства контроля за их обслуживанием.
Если ваша рабочая нагрузка может выдерживать нечастые зависания продолжительностью в пару секунд (что обычно так и есть) или если вам достаточно 15 минут для подготовки этих зависаний (например, путем истощения текущих подключений и отказа от новых), модель хостинга по умолчанию с Общие хосты идеальны, поскольку обеспечивают масштабируемость и простоту управления.
С другой стороны, если ваша рабочая нагрузка очень чувствительна к зависаниям, даже на несколько секунд, вам следует рассмотреть возможность использования выделенного хоста Azure, который даст вам контроль над обслуживанием.
Microsoft все еще работает над улучшением управления обслуживанием общих хостов, поэтому нет сомнений, что с моделью общих хостов ситуация будет становиться все лучше и лучше.
2024-03-27 16:30:18
1711943929
#Практическое #руководство #по #минимизации #сбоев

