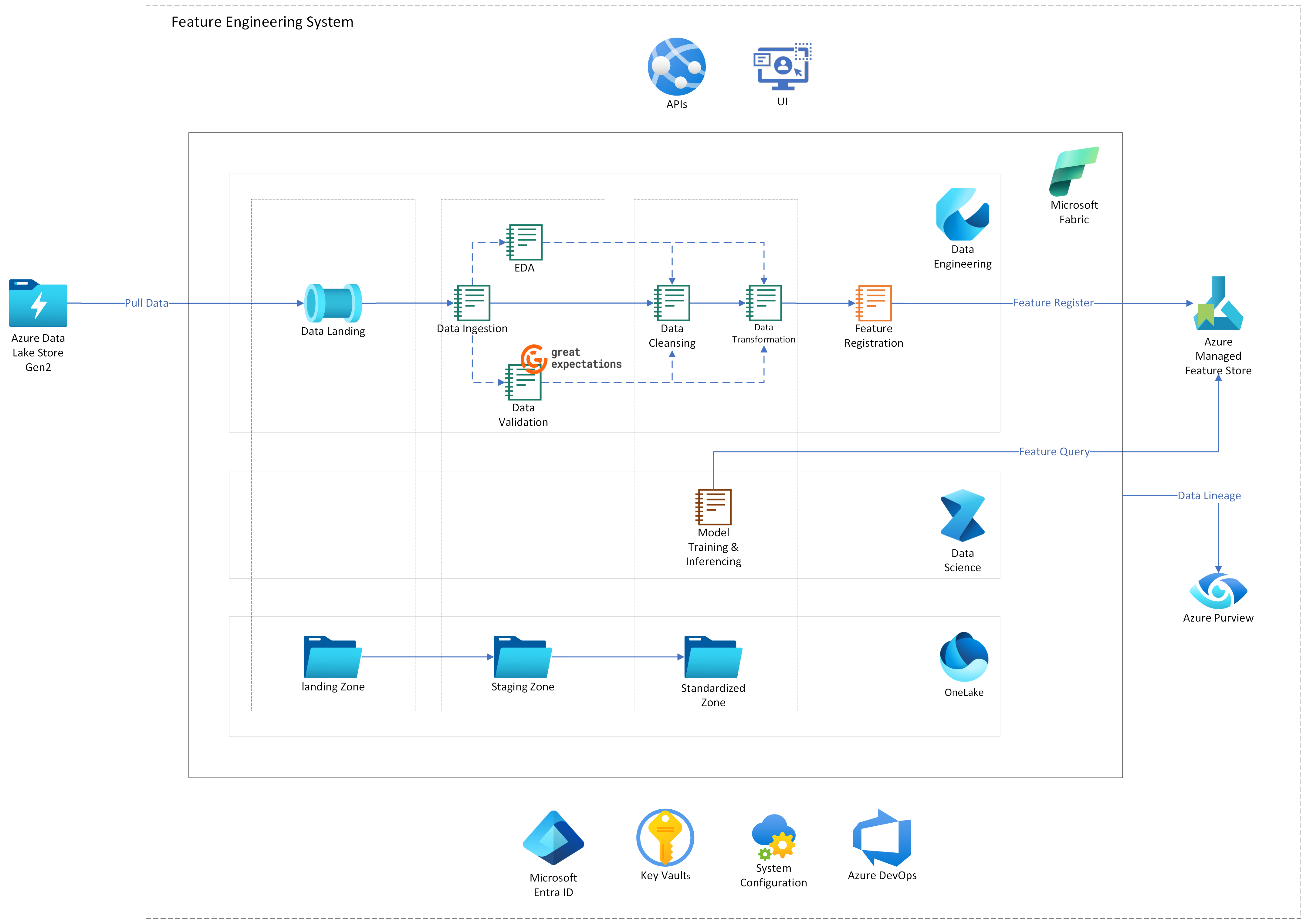
Особенность инженерной системы
Разработка функций — это процесс использования знаний предметной области для извлечения функций (характеристик, свойств, атрибутов) из необработанных данных. Извлеченные функции используются для обучения моделей, которые могут прогнозировать значения для соответствующих бизнес-сценариев. Система разработки функций предоставляет инструменты, процессы и методы, используемые для последовательного и эффективного выполнения разработки функций.
В этой статье подробно описано, как создать систему разработки функций на основе хранилища управляемых функций машинного обучения Azure и Microsoft Fabric.
Представьте себе следующий сценарий:
Гэри, специалист по обработке данных в компании Contoso, работает над важным проектом. Он стремится выяснить, когда спрос на автомобильные онлайн-услуги самый высокий. Для этого он использует два основных источника информации. Одним из них являются общедоступные данные о поездках на такси в Нью-Йорке. Другой — частные записи транспортных компаний. Работа Гэри внезапно остановилась, когда он не смог получить доступ к необходимым данным. Это произошло потому, что Бо, инженер по данным, был недоступен. Эта ситуация показала, насколько проект Гэри зависит от способности команды управлять данными внутри компании. Когда Бо вернулся, все увидели, насколько им нужна система автоматического перемещения данных. Эта система облегчит работу и поможет специалистам по обработке данных и инженерам Contoso лучше работать вместе.
Этот сценарий подчеркивает проблемы доступности данных и важность автоматизации для оптимизации рабочих процессов с данными.
Наша Архитектура
Как показано на диаграмме архитектуры, при работе на Microsoft Fabric конвейер данных обрабатывает, принимает и преобразует входящие данные. Преобразованные данные регистрируются как функции в хранилище управляемых функций машинного обучения Azure. После этого функции готовы к использованию для обучения модели и получения логических выводов. Тем временем Purview отслеживает и контролирует происхождение данных как в конвейере данных, так и в функциях.
Поток данных
Следующий поток данных соответствует предыдущей диаграмме:
- Место размещения данных: данные копируются из Azure Data Lake Storage Gen2 и передаются в зону размещения Lakehouse.
- Прием данных: данные принимаются из зоны приземления в промежуточную зону.
- (Необязательно) EDA: ученые, работающие с данными, анализируют и исследуют данные для получения сводных характеристик.
- (Необязательно) Проверка данных: данные проверяются, чтобы убедиться, что они соответствуют требованиям для следующих шагов.
- Преобразование данных: данные преобразуются в функции в стандартной зоне и сохраняются в хранилище управляемых функций Машинного обучения Azure.
- Обучение модели и вывод: функции используются для обучения модели и вывода.
- Происхождение данных: Purview отслеживает и контролирует конвейер данных и функции.
Компоненты
- Azure Data Lake Storage 2-го поколения используется для хранения данных.
- Microsoft Ткань используется в качестве оркестратора конвейера данных и хранилища данных и моделей. Он предоставляет набор интегрированных сервисов, которые позволяют вам принимать, хранить, обрабатывать и анализировать данные в единой среде.
- Хранилище управляемых функций машинного обучения Azure используется для хранения функций и управления ими. Это позволяет специалистам по машинному обучению самостоятельно разрабатывать и обнаруживать функции.
- сфера деятельности (ранее известный как Каталог данных Azure) обеспечивает унифицированное управление данными для отслеживания происхождения и мониторинга активов данных.
Конвейер данных
Microsoft Fabric предоставляет набор интегрированных служб, которые позволяют принимать, хранить, обрабатывать и анализировать данные в единой среде. Конвейер данных Microsoft Fabric, который помогает создавать потоки данных и управлять ими. Он работает с другими компонентами, такими как Lakehouse и хранилище данных, обеспечивая комплексное решение для обработки данных. Его также можно использовать в качестве конвейера для координации перемещения и преобразования данных. Он позволяет решать самые сложные сценарии извлечения, преобразования и загрузки (ETL).
В нашем примере конвейер состоит из нескольких действий, и каждое действие отвечает за конкретную задачу, такую как подача данных, прием данных, очистка данных, преобразование данных. В этом случае мы используем конвейер для загрузки данных из веб-приложения, а затем сохраняем данные в хранилище Fabric One Lake. После этого мы будем использовать данные для создания функций и сохранения их в хранилище управляемых функций Машинного обучения Azure. Наконец, мы используем функции для обучения и вывода модели.

Валидация данных
Большие Надежды — это библиотека Python, предоставляющая основу для описания приемлемого состояния данных и последующей проверки соответствия данных этим критериям.
Мы используем Great Expectations для проверки данных и экспортируем журналы в Azure Log Analytics или Azure Monitor для создания отчетов о качестве данных и используем документы данных, которые отображают ожидания в чистом, удобном для чтения формате.
Магазин функций
Хранилище управляемых функций машинного обучения Azure (MFS) оптимизирует разработку машинного обучения, предоставляя масштабируемую, безопасную и управляемую среду для управления функциями.
Функции — это важные входные данные для вашей модели машинного обучения, представляющие атрибуты, характеристики или свойства данных, используемых при обучении. В MFS набор функций — это группа связанных функций. Набор функций можно определить с помощью спецификации в формате yaml, например, следующим образом.
$schema: http://azureml/sdk-2-0/FeatureSetSpec.json
source:
type: csv
path: {source_path}
timestamp_column:
name: pickup_timestamp
features:
- name: hour_pickup
type: integer
- name: weekday_pickup
type: integer
- name: scaled_demand
type: double
index_columns:
- name: borough_id
type: integer
В нашем примере регистрация набора функций легко интегрируется в конвейер данных и происходит за один шаг после процесса преобразования данных.
После регистрации набор функций размещается в MFS. Исходные данные после обработки и преобразования теперь находятся в Fabric OneLake, что делает их легко доступными и управляемыми. Одновременно с этим особенности набора функций тщательно каталогизируются в Purview, обеспечивая всестороннее и организованное представление метаданных данных.
Обучение модели и вывод
Обучение модели в машинном обучении включает в себя создание математической модели, которая обобщает и обучается на основе обучающих данных. В этом процессе используется регрессия опорных векторов из пакета sklearn для обучения модели анализу данных. В регрессионном анализе целью обучения модели является разработка вероятностной модели, которая точно отображает взаимосвязь между зависимыми и независимыми переменными. Управление экспериментами упрощается с помощью API MLflow, который предлагает структурированный подход к отслеживанию показателей, параметров и результатов экспериментов.
Процесс обучения модели включает в себя несколько шагов для эффективной подготовки и анализа данных. Первоначально соответствующие столбцы функций, такие как borough_id и будний_день_самовывоз, выбираются из набора данных. Затем данные делятся на наборы для обучения и тестирования, при этом для обучения модели применяется регрессия опорных векторов, при этом Scaled_demand рассматривается как зависимая переменная, а все остальные — как независимые переменные. MLflow играет решающую роль в отслеживании показателей обучения, параметров и окончательной модели регрессии опорного вектора. После завершения создания модели она сохраняется для дальнейшего отслеживания, что позволяет упростить управление и сравнение различных версий модели. Эту сохраненную модель позже можно загрузить для целей вывода, где она запускается на образце набора данных, чтобы продемонстрировать ее прогностические возможности.
Родословная данных
Происхождение данных охватывает жизненный цикл данных, отслеживая их происхождение и перемещение по массиву данных. В Microsoft Fabric встроенное представление происхождения помогает пользователям понять поток данных от источника к месту назначения.
Например, в случае использования машинного обучения пользователи могут изучить, как обучается модель обнаружения мошенничества, и углубиться в соответствующие узлы. Хотя предоставленный вариант использования иллюстрирует обработку данных на уровне артефактов Fabric (например, Lakehouse, блокноты и эксперименты), более подробные сведения, такие как исходные данные, обрабатываемые в блокноте Fabric, или место хранения обработанных данных, требуют представления происхождения. с более детальными активами данных.
В следующих разделах мы описываем индивидуальный подход к регистрации такого детального происхождения данных в Microsoft Purview.
Происхождение конвейера данных
Чтобы иметь детальное сквозное представление о происхождении логики обработки конвейера данных, мы могли бы зарегистрировать обработанные файлы/таблицы в качестве активов данных в Purview, от размещенных исходных файлов в целевой зоне до преобразованных файлов, сохраненных в зоне стандартизации. . В конце каждого блокнота Fabric для обработки данных у нас есть логика для сбора и регистрации активов данных и соответствующих линий передачи данных в Purview с использованием API-интерфейсов Purview REST.

Особенности происхождения
После регистрации определяемых пользователем функций в хранилище управляемых функций машинного обучения Azure можно также применить аналогичную пользовательскую логику для регистрации подробного происхождения функций в Purview.
В представлении происхождения функций давайте обратим внимание на активы функций (во втором столбце). Это показывает, что все функции происходят из преобразованных данных, сгенерированных на этапе преобразования конвейера данных. Конечные пользователи могут проследить путь происхождения еще дальше назад, чтобы глубже понять жизненный цикл обработки данных.

Модель машинного обучения Lineage
Представление о происхождении модели машинного обучения играет решающую роль в происхождении данных. Он предоставляет информацию о функциях, используемых для обучения модели машинного обучения, идентифицирует записную книжку, содержащую исходный код, находит детали запуска обучающего эксперимента и демонстрирует показатели производительности.

Возможные варианты использования
- Модель рекомендаций видеоклипов опирается на функции профиля пользователя. Специальная группа постоянно обновляет все профили пользователей, обычно ежедневно. Чтобы модель обучения работала оптимально, она должна иметь доступ к самым последним значениям функций, которые соответствуют меткам обучения и алгоритмам рекомендаций. Использование системы разработки признаков становится выгодным, когда в модели обучения задействовано множество аналогичных функций.
- Рассмотрим на примере особенности профиля пользователя. Весьма вероятно, что эти функции служат не только модели рекомендаций видеоклипов, но и различным другим моделям. Различные команды, использующие эти модели, могут использовать общие функции для всех команд, что приводит к значительной экономии вычислительных затрат и сокращению времени обучения.
Связанные ресурсы
Разверните реализацию по следующей ссылке:
Следующие шаги
2024-03-13 22:50:40
1710659207
#Создайте #свою #систему #разработки #функций #на #базе #управляемого #хранилища #функций #AML #Microsoft #Fabric